[자료구조] 인접 행렬과 인접 리스트(adjacency list) 문제 풀이 1 (tistory.com)
[자료구조] 인접 행렬과 인접 리스트(adjacency list) 문제 풀이 1
본격적인 문제 풀이에 앞서, adjacency matrix가 무엇인지부터 짚어보도록 하자. 인접 행렬 (Adjacency Matrix)인접 행렬은 그래프를 표현하는 방법 중 하나로,그래프의 모든 노드 쌍에 대해 엣지(간선)
with-mimi.tistory.com
* 위 포스팅과 바로 이어지는 문제이므로, 위 글을 먼저 읽고 오길 바란다.
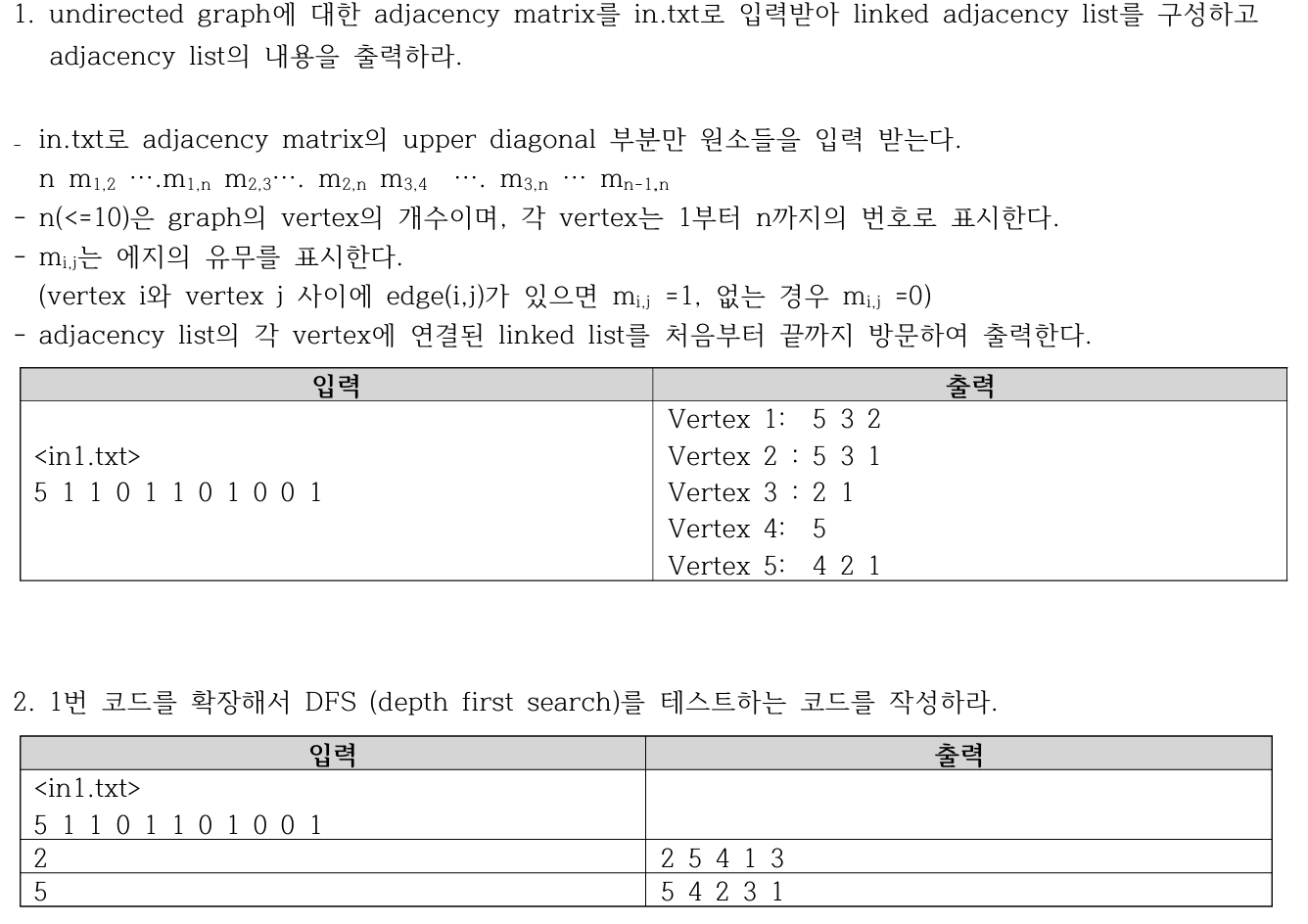
지난 포스팅에서 1번 문제에 대한 풀이를 다룬 바 있으므로,
오늘은 2번 문제를 함께 풀어보겠다.
본격적인 풀이에 앞서, DFS(depth first search)가 무엇인지부터 알아보자.
그래프 탐색
: 하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것.
=> 종류 : 깊이 우선 탐색(DFS), 넓이 우선 탐색(BFS)
=> 전위 순회, 중위 순회, 후위 순회와 같은 트리의 순회 방법들도 모두 그래프 탐색에 포함됨.
깊이 우선 탐색(depth first search)
: 임의의 노드에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법.
그래프의 모든 간선을 조회한다.
- 보통 모든 노드를 방문하고자 하는 경우 이 방법을 선택한다.
- 쉽게 예를 들자면, 미로에서 한 방향으로 갈 수 있을 때까지 계속해서 가다가 막다른 길이 나왔을 때 다시 가장 가까운 갈림길로 돌아와서 그곳에서부터 다시 같은 방법으로 탐색을 진행하는 것과 유사하다.
- 자기 자신을 호출하는 순환 알고리즘의 형태이다.
- 전위 순회를 포함한 모든 다른 형태의 트리 traversal은 DFS의 한 종류이다 !
- DFS를 이용해 그래프 탐색을 진행할 경우 대부분, 어떤 노드를 방문했었는지 여부를 반드시 검사해 두어야 한다.
다시 문제로 돌아와서, 1번문제에서 dfs 기능을 추가해야 하는 이 문제를 풀어보자.
앞서 말한 바와 같이, DFS를 이용해 그래프 탐색을 진행할 경우, 어떤 노드를 방문했었는지 여부를 반드시 검사해 두어야 한다. 재차 방문하지 않도록 장치를 두어야 하기 때문이다. 따라서 나는 visited 배열을 아래와 같이 두고 초기화해 두었다.
#define FALSE 0
#define TRUE 1
#define MAX_VERTICES 10
int visited[MAX_VERTICES];
for (int i = 0; i < MAX_VERTICES; i++)
{
visited[i] = FALSE;
}
그리고 이번에는 in.txt로부터 입력값을 받은 후, 사용자로부터 숫자 scanf 입력이 추가적으로 들어올 것이다. DFS를 해당 숫자 노드부터 시작한다고 보아도 무방하다.
입력값으로 2가 들어왔다고 가정해 보자.
1번 문제를 통해 우리는 arr[2]= 5-> 3-> 1 리스트임을 안다. 이를 염두에 두고, dfs 함수 코드를 살펴보자.
void dfs(Node *arr[], int v)
{
Node *w;
visited[v] = TRUE;
printf("%d ", v);
for (w = arr[v]; w; w = w->next)
{
if (!visited[w->vertex])
{
dfs(arr, w->vertex);
}
}
}
여기서 우리는 매개변수 v로 2를 받은 상황이다. 그럼 일단 정점 2를 지났다는 가정이므로 바로 visted[2]=TRUE로 바꾸어 준 후 출력도 진행한다. 이 다음부터가 중요한데,
for (w = arr[v]; w; w = w->next)
{
if (!visited[w->vertex])
{
dfs(arr, w->vertex);
}
}
for문의 조건문을 보면, 지금은 값이 arr[2]인 w를 계속해서 ->next 시켜주는 모습이다. arr[2]가 NULL이 될 때까지 말이다.
그렇다면.. *** arr[2]= 5-> 3-> 1 리스트 *** 를 생각하며 따라왔을 때,
1. w=arr[2]->next = arr[5]
2. (!visited[5])는 성립(아직 visited[2]만 TRUE인 상태이므로)
3. dfs(arr,5) 호출됨
4. visited[5]=TRUE로 변환
5. "5" 출력됨
6. w=arr[5]->next= arr[4]
7. (!visited[4]) 성립
8. dfs(arr,4)호출
.
.
와 같은 과정으로 이어질 것을 예상해볼 수 있다.
따라서 우리는 scanf로 2를 받았을 때 출력값을

위와 같이 받아볼 수 있다.
DFS의 원리를 이해하고 있어야 더 쉽게 접근할 수 있는 문제였다.
전체 코드를 남겨두며 포스팅을 마친다.
#include <stdio.h>
#include <stdlib.h>
#define FALSE 0
#define TRUE 1
#define MAX_VERTICES 10
int visited[MAX_VERTICES];
typedef struct Node
{
int vertex;
struct Node *next;
} Node;
Node *createNode(int vertex)
{
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->vertex = vertex;
newNode->next = NULL;
return newNode;
}
void addEdge(Node *arr[], int i, int j)
{
Node *newNode = createNode(j);
newNode->next = arr[i];
arr[i] = newNode;
newNode = createNode(i);
newNode->next = arr[j];
arr[j] = newNode;
}
void dfs(Node *arr[], int v)
{
Node *w;
visited[v] = TRUE;
printf("%d ", v);
for (w = arr[v]; w; w = w->next)
{
if (!visited[w->vertex])
{
dfs(arr, w->vertex);
}
}
}
int main()
{
FILE *f = fopen("in.txt", "r");
int n = 0;
fscanf(f, "%d", &n);
Node *arr[10] = {NULL};
int value = 0;
for (int i = 1; i < n; i++)
{
for (int j = i + 1; j <= n; j++)
{
fscanf(f, "%d", &value);
if (value == 1)
{
addEdge(arr, i, j);
}
}
}
int m = 0;
scanf("%d", &m);
for (int i = 0; i < MAX_VERTICES; i++)
{
visited[i] = FALSE;
}
dfs(arr, m);
fclose(f);
return 0;
}'자료구조' 카테고리의 다른 글
| [자료구조] BT level order traversal 문제 풀이 (Queue 사용) (1) | 2024.06.14 |
|---|---|
| [자료구조] quicksort algorithm 문제 (1) | 2024.06.12 |
| [자료구조] inserting sort 문제 REVIEW (1) | 2024.06.12 |
| [자료구조] BST delete 함수 작성해보기 (2) | 2024.06.10 |
| [자료구조] BST insert, inorder traversal 문제 REVIEW (2) | 2024.06.10 |